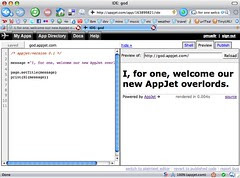
AppJet. Have you heard of it?
There's plenty of rocks that can be thrown here.
- All my code needs to go in ONE file?
- No static resources?
- Seemingly overly-general db approach, probably yielding terrible performance
- Where's my debugger?
But there's a whole lot more to like than dislike with AppJet. Like most of the new-fangled things on the web, I enjoy looking and learning, as a breath of fresh air in spaces that we've become too comfortable with; spaces where we've not done enough thinking outside the box (hello, relational databases!). That said, here are some thoughts.
I've been kidding my Rational brethren for years that Eclipse is dead *, everything's happening on the web, we'll using web-based IDEs in the near future. A chuckle generator for sure. Time's up though, folks. The future is here. Or at least getting very, very close.
There's lots of challenges in this space, you can see even from just a bit of playing around with AppJet. The code editing is flakey. (Peruse it with FireBug; I'm amazed it works as well as it does, honestly, given the implementation as rendering of HTML DOM; it's amazing, actually). I need to be able to edit more than one resource - I certainly don't want to have to have all my code lumped in one file; actually, I don't care if it's one file in the end, but I don't want to see it that way in the IDE. And clearly we need to be able to edit other things like HTML bits, CSS bits, etc.
It's pretty clear to me that Eclipse is too much, and AppJet is not enough, in terms of IDE capabilities, for a space like this. Whadya think - is it easier to remove function from Eclipse, or add function to AppJet? And I worry that Eclipse is veering off on a tangent (runtimes) when there is clearly plenty of work to be done in the IDE space; maybe not in the Java-hosted IDE space - what more does Eclipse really need? But what about spreading the love a little?
The code editing itself was flakey enough that I ran this on Safari just so I could see how well "Edit in TextMate" would work. It did work, but then I have two separate applications open for my "IDE", and that quickly got out of sync. Here's what I'm wondering. If these new-fangled client-based VMs (Silverlight, Flex) are really up to snuff, it should be possible to build a new text editor component with them. From scratch, painting glyphs on the canvas with low-level graphics calls. How do you think Eclipse's rich text editors work, anyway?
Then there's the database. From 50K feet, there's some similarity to couchdb here. The programming language is JavaScript, the objects stored are constrained JavaScript objects, etc. Lots of dissimilarities as well; with couchdb you have a single 'document store' with associated views; with AppJet you have multiple StorageContainers. With couchdb, an alternate 'view' of the database (filters, keyed differently, etc) are available transiently and persistently; with AppJet, the views are always transient (a classic time vs. space trade-off. Hint: storage is sometimes cheaper than time).
Just in terms of raw db functionality, what's nice is that there's not much there; just a set of simple operations you can perform against the db. You have to imagine the performance is going to be terrible on this, especially the filter/view operations. But it's clearly an interesting angle to take in the db space, and one I welcome. SQL has always given me the cold pricklies. I hope that the work that's gone on in recent years introducing XML (another thing you happily won't find in AppJet) into the database world, might have paved the way for JSON and JavaScript. Are you listening, Anant?
This space, in general, has lots of low fruit to be picked; it's great to see things like AppJet making a run for it. I certainly hope that someone doesn't buy them and then send them to a dark place.
For more info, Dion Almaer posted a short interview with an AppJet dev yesterday.
* update on 2007/12/13 at 1:00pm
Of course, no direct offense to Eclipse meant here; I use it on a daily basis, and simply couldn't live without it. I meant to implicate the whole notion of desktop-based development, Eclipse being my flavorite for Java, in light of our new web-based IDE overlord takeover; or at least the possibility of that happening. I'll try to attack things in a more broad sense in the future. :-)



















{kind=link}